Chatbot, Copilot, or Agent? Who Owns the Loop
Same frontier models, wildly different products—the while-loop behind agents, production exit paths, and a minimal TypeScript harness.
ChatGPT and Claude Code can run the same model family, yet they feel nothing alike. One answers when you ping it; the other reads files, runs commands, fixes tests, and only stops when the task is done.
The gap is not “smarter weights.” It is who owns the control loop.
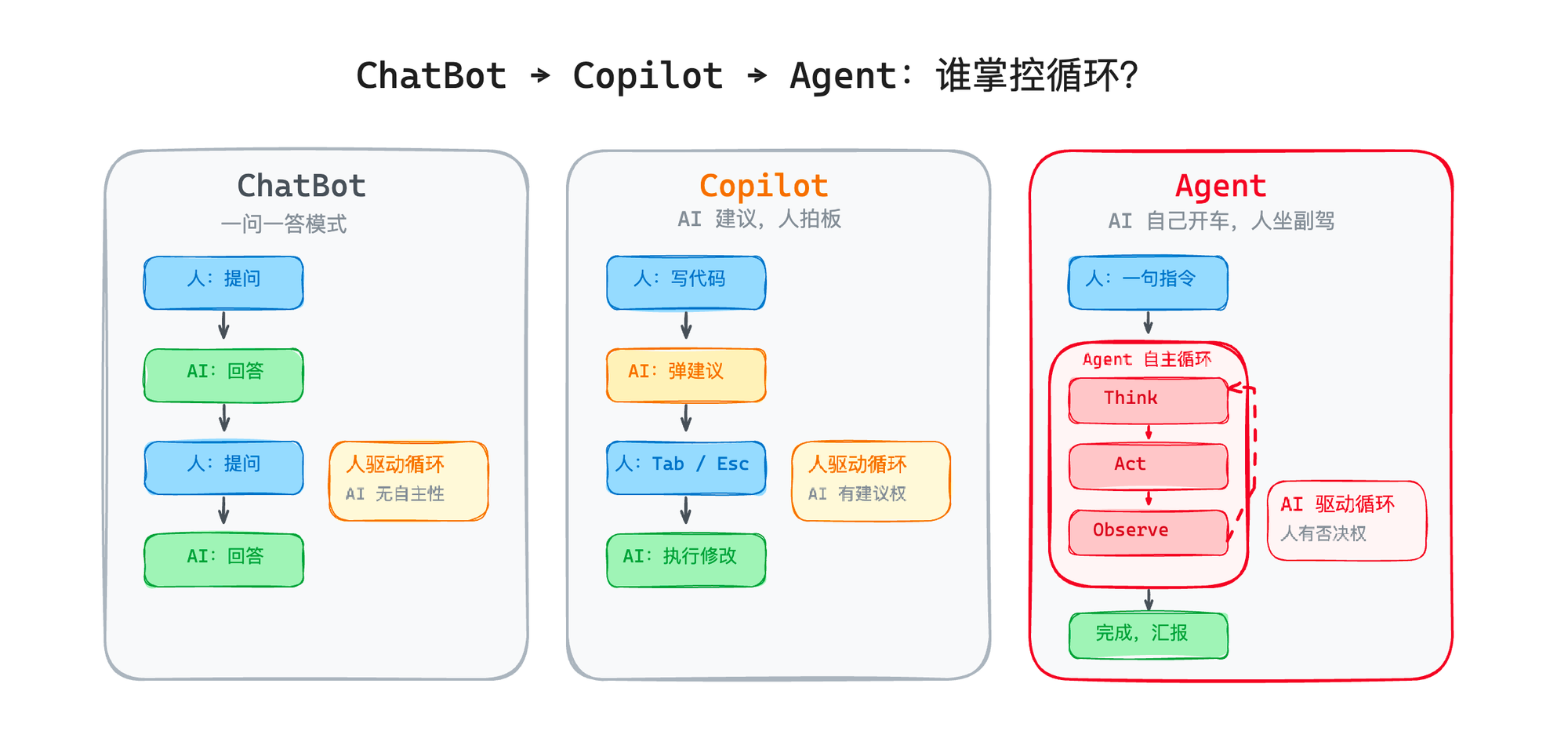
Three modes
Chatbot — human drives every turn
You: What's the weather in Beijing?
AI: Sunny, high 25°C.
(done)No tool autonomy. Silence means stop.
Copilot — AI suggests, you accept
Tab completion in Cursor is Copilot-shaped: it predicts the next edit, but you accept or reject. It will not run your test suite across the repo on its own.
Agent — AI drives, you veto
You: Migrate this service from Express to Hono
AI: Read routes → install hono → rewrite handlers → run tests → fix types → report 8 files changedOne sentence from you; many think → act → observe cycles from the model.
Anthropic’s framing: in a workflow, code orchestrates the LLM; in an agent, the LLM chooses tools and next steps. “Chooses” is the keyword.
Minimal agent: while (true)
while (true) {
const response = await llm.chat(messages);
if (response.toolCalls.length === 0) break;
for (const toolCall of response.toolCalls) {
const result = await executeTool(toolCall);
messages.push(result); // observe — non-negotiable
}
}Design notes:
while (true)— step count is unknown until the task finishes.- Stop when no tool calls — model signals done (or gives up).
messages.push(result)— without observations, the next turn is blind.
That is ReAct: reason, act, observe. Old paper, current product standard.
Production loops are not 10 lines
The same skeleton in Claude Code spans serious engineering around it.
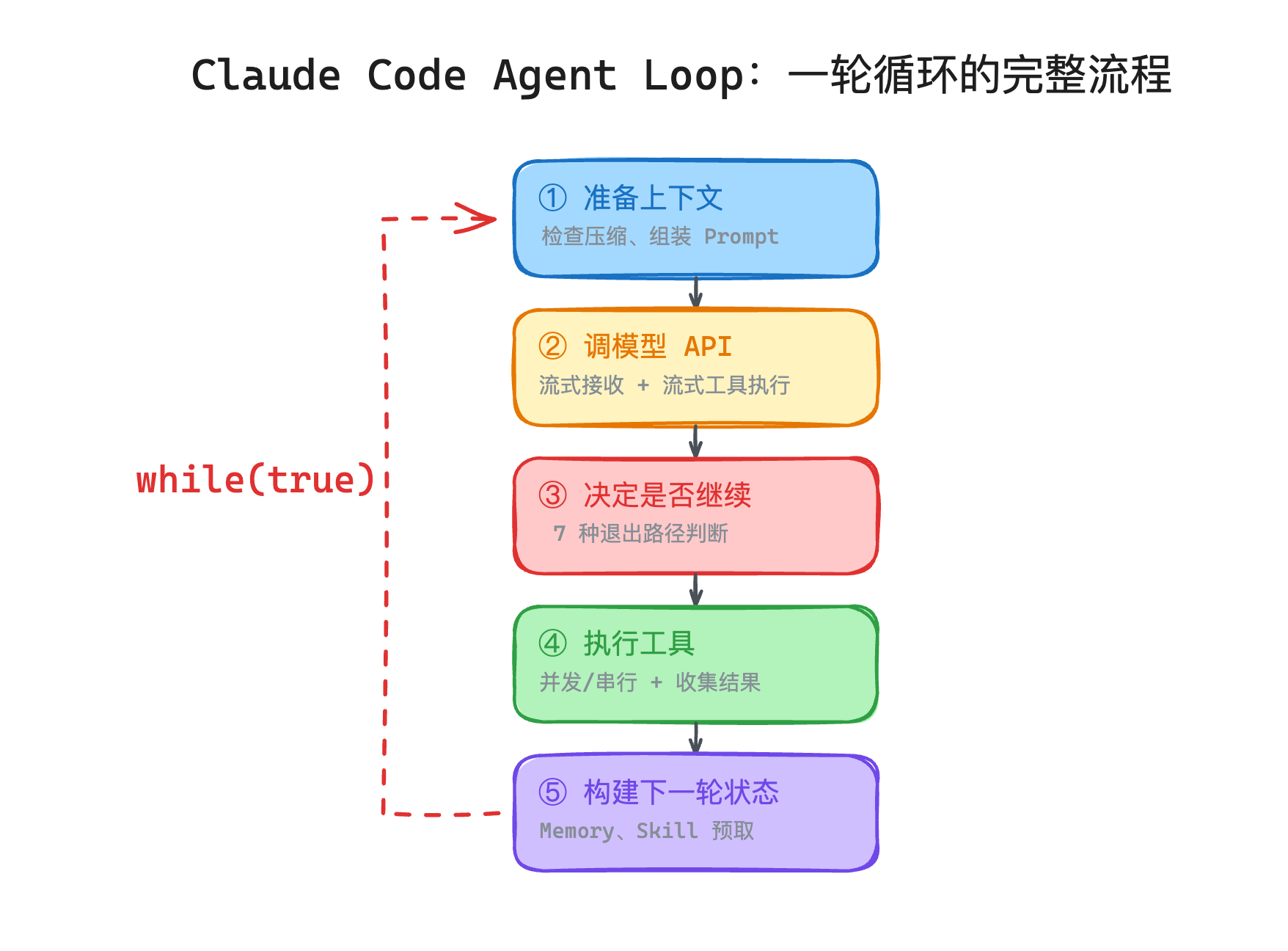
Prepare context — trim, snip, or summarize before the window blows up (ties to memory as context budget).
Call the model — stream tokens; start read-only tools as soon as calls are parsed (don’t wait for the full assistant message).
Continue or exit — not only “any tool calls?” Production needs paths for user abort, max turns, hook veto, context limit, prompt still too long after compression, etc.
Execute tools — failures must return structured errors so the model can recover.
Housekeeping — queued attachments, skill discovery, memory prefetch—then next turn.
State beyond messages — turn index, last exit reason, compression stats, partial output recovery. Debugging “why did it stop?” needs that audit trail.
Transparency — minutes of work cannot be a spinner. Stream thoughts, tool names, and results (generators / SSE) so humans can interrupt bad plans early.
Behaviors that emerge from the loop
On a real trace (add retry to fetchUser), good agents:
- Read before write — inspect file, search for existing
withRetry, reuse instead of reinventing. - Self-correct after observe — notice missing import after edit.
- Verify — run tests; “done” without verify is a prompt design problem, not luck.
Those are not hard-coded; they come from tight observe feedback and constraints. Making them reliable is the engineering job.
Toy harness (~30 lines)
async function agent(task: string) {
const messages = [{ role: "user", content: task }];
let turnCount = 0;
const maxTurns = 30;
while (true) {
if (++turnCount > maxTurns) break;
const result = await generateText({
model,
messages,
tools,
maxSteps: 1, // outer loop stays ours
});
if (result.toolCalls.length === 0) {
console.log(result.text);
break;
}
for (const call of result.toolCalls) {
const toolResult = await executeTool(call);
messages.push(
{ role: "assistant", toolCalls: [call], content: result.text },
{ role: "tool", content: toolResult, toolCallId: call.toolCallId },
);
}
}
}Missing vs production: streaming, parallel safe tools, compression, retries, permissions, loop detection.
For a full-stack chat workspace (sessions, streaming, multi-provider keys), see the open-source My AI Studio project. For a minimal coding-agent harness, see how I built Mini Claude Code.
Summary
| Mode | Loop owner | Best for |
|---|---|---|
| Chatbot | Human | Q&A, drafting |
| Copilot | Human (+ suggestions) | In-editor speed |
| Agent | Model (human veto) | Multi-step engineering tasks |
If you are hiring for AI features on a website or internal tool, ask whether you need a chat box or an owned loop with tools, memory, and guardrails—that choice drives architecture more than the model badge on the box.