Beyond Storing Vectors: A Production-Style RAG Pipeline with Milvus
An EPUB semantic Q&A walkthrough—loaders, splitters, Milvus schema, retrieval parameters, and prompt boundaries that map to enterprise knowledge bases.
Many teams treat RAG as: chunk → embed → drop into a vector DB → attach an LLM. It runs in a notebook; it rarely survives production scrutiny.
Real friction is whether the pipeline has clear roles: how to load, how to chunk, what metadata to keep, how to pack hits for the model, which knobs tune recall vs maintainability.
This post uses an EPUB novel Q&A demo—the same shape as internal handbooks, product docs, or support libraries.
RAG is not “plug in Milvus.” It is a chain of Loader, Splitter, Embedding, Retriever, Prompt, and LLM with explicit boundaries. Milvus is the recall infrastructure, not the whole system.
Why MySQL keyword search fails here
You have an EPUB of a long novel. User asks:
What martial arts does Duan Yu know?
Keyword search wants exact tokens. The text may list Six Meridians Sword, Lingbo Footwork, Beiming Divine Skill—not the phrase “martial arts.” That is semantic recall, not LIKE '%Duan Yu%'.
Keywords win for order IDs and error codes; they lose when wording diverges but meaning aligns.
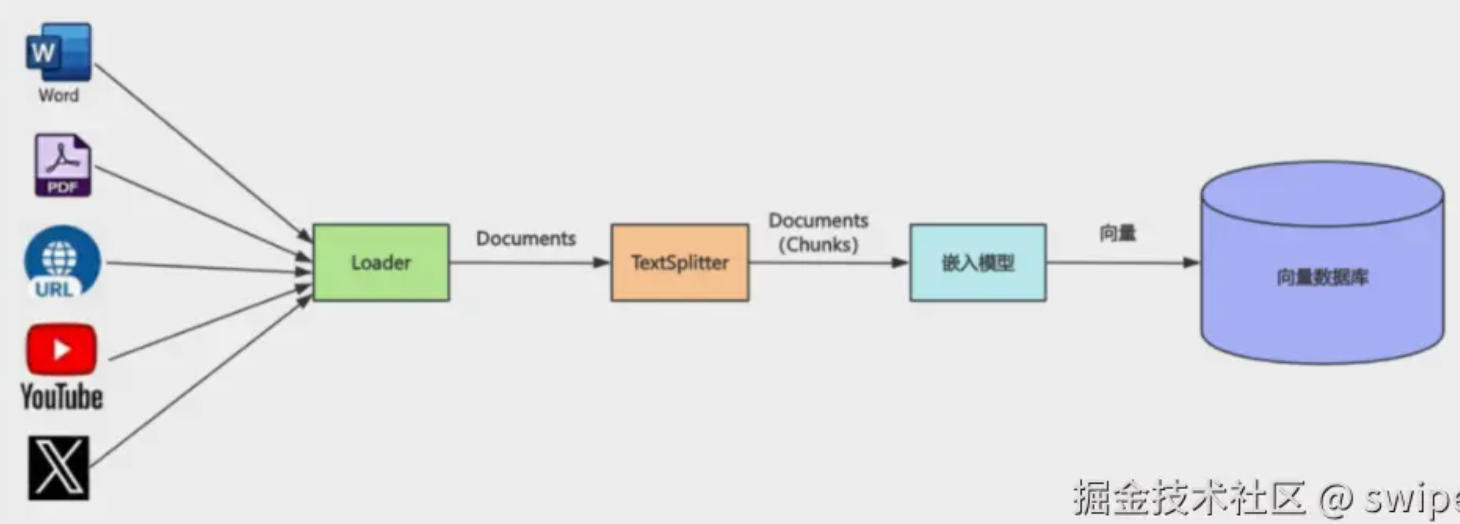
Six roles in the pipeline
- Loader — ingest raw documents
- Splitter — chunks sized for retrieval
- Embedding — text → vectors
- Vector DB (Milvus) — store + similarity search
- Retriever — top‑k interface
- LLM + prompt — answer from evidence
Clarifications:
- Embeddings do not chat; they align questions and passages in vector space.
- Milvus does not “understand” text; it finds nearest neighbors fast.
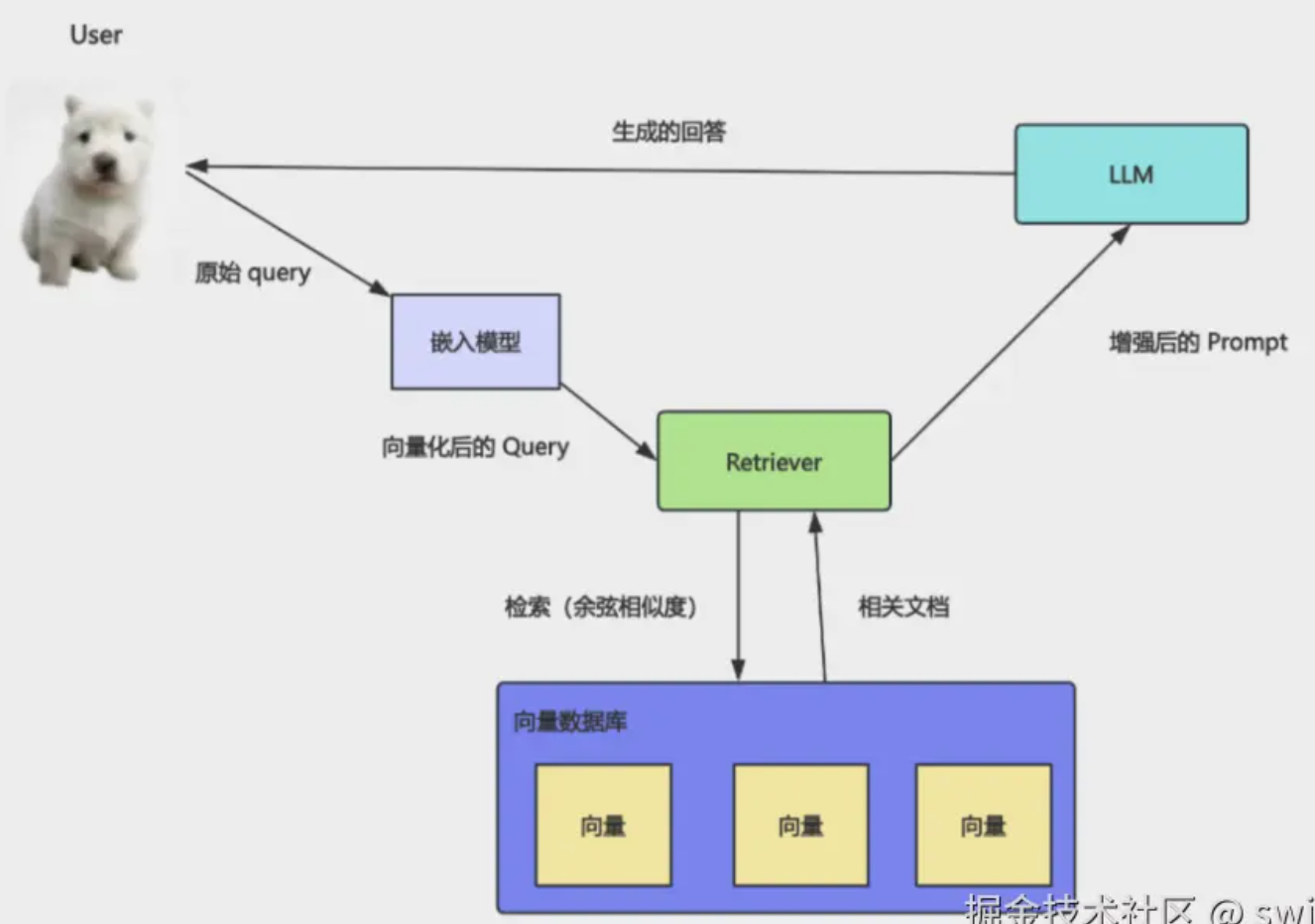
At query time:
- Embed the question
- Milvus returns closest chunks
- Build context + prompt
- LLM synthesizes the answer
Step 2 alone is semantic search. Step 4 is RAG.
Why not paste the whole book into the LLM?
- Context is finite and expensive — long prompts cost more and dilute attention.
- Generation ≠ efficient recall — asking the model to “find the answer” in 500k tokens is brittle and pricey.
- Engineering pattern: narrow then reason — vector recall shrinks candidates; the LLM reads a small evidence set.
Same mental model as search: recall → rank (here, LLM is the final synthesizer).
Ingestion: EPUB → Milvus
EPUB is just unstructured docs; the pattern transfers to policies, manuals, and wikis.
Load by structure
import { EPubLoader } from "@langchain/community/document_loaders/fs/epub";
async function loadBook(filePath) {
const loader = new EPubLoader(filePath, { splitChapters: true });
return loader.load();
}Chapter boundaries beat one giant string—splitters keep cleaner context.
Two-stage splitting
- Structural cut (chapters)
- Window split inside each chapter
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});chunkSize— trade mixed themes (too big) vs fragments (too small). ~500 chars is a sane Chinese/long-text starting point.chunkOverlap— reduces boundary cuts through critical sentences.- Recursive splitter — boring but stable default before semantic chunkers.
Schema: vectors + explainable metadata
Anti-pattern: store only vector and wonder what matched.
Useful fields:
id,book_id,book_name,chapter_num,chunk_index,content,vector
import {
MilvusClient,
DataType,
IndexType,
MetricType,
} from "@zilliz/milvus2-sdk-node";
const COLLECTION_NAME = "ebook_collection";
const VECTOR_DIM = 1024;
async function ensureCollection(client) {
const { value: exists } = await client.hasCollection({
collection_name: COLLECTION_NAME,
});
if (!exists) {
await client.createCollection({
collection_name: COLLECTION_NAME,
fields: [
{ name: "id", data_type: DataType.VarChar, is_primary_key: true, max_length: 100 },
{ name: "book_id", data_type: DataType.VarChar, max_length: 100 },
{ name: "book_name", data_type: DataType.VarChar, max_length: 200 },
{ name: "chapter_num", data_type: DataType.Int32 },
{ name: "chunk_index", data_type: DataType.Int32 },
{ name: "content", data_type: DataType.VarChar, max_length: 10000 },
{ name: "vector", data_type: DataType.FloatVector, dim: VECTOR_DIM },
],
});
await client.createIndex({
collection_name: COLLECTION_NAME,
field_name: "vector",
index_type: IndexType.IVF_FLAT,
metric_type: MetricType.COSINE,
params: { nlist: 1024 },
});
}
await client.loadCollection({ collection_name: COLLECTION_NAME });
}- Schema — future citations and filters
- Index — latency at scale
- loadCollection — online search readiness
Write path: embed once per chunk
async function buildChunkRows(chunks, bookId, bookName, chapterNum) {
return Promise.all(
chunks.map(async (content, chunkIndex) => ({
id: `${bookId}_${chapterNum}_${chunkIndex}`,
book_id: String(bookId),
book_name: bookName,
chapter_num: chapterNum,
chunk_index: chunkIndex,
content,
vector: await embeddings.embedQuery(content),
})),
);
}Deterministic IDs (book + chapter + index) aid debugging. Offline embedding at ingest vs online embedding for queries splits cost correctly.
Query path: Milvus recalls, LLM answers
Vector search
async function retrieveRelevantChunks(client, question, topK = 3) {
const questionVector = await embeddings.embedQuery(question);
const result = await client.search({
collection_name: COLLECTION_NAME,
vector: questionVector,
limit: topK,
metric_type: MetricType.COSINE,
output_fields: ["book_name", "chapter_num", "chunk_index", "content"],
});
return result.results;
}- COSINE — common default for text embeddings (direction similarity).
- topK — not “more is better”; 3–5 is a typical demo band.
- output_fields — only what the prompt needs.
Prompt with boundaries
function buildPrompt(question, context) {
return `
You answer from ebook excerpts only. Do not invent plot.
Excerpts:
${context}
Question: ${question}
Rules:
1. Ground answers in excerpts
2. Merge multiple excerpts when needed
3. Say "insufficient evidence" when unsure
4. Keep names and terms accurate
`.trim();
}Without “evidence only,” the model blends parametric knowledge with retrieved text—bad for trust.
Full answer function
async function answerQuestion(client, question) {
const chunks = await retrieveRelevantChunks(client, question, 5);
if (!chunks.length) {
return "No sufficiently relevant passages were retrieved.";
}
const context = buildContext(chunks);
return (await chatModel.invoke(buildPrompt(question, context))).content;
}Milvus finds; LLM explains. When quality drops, you can tell recall vs prompt vs model issues apart.
Parameters worth understanding
| Knob | Effect |
|---|---|
chunkSize | Semantic density vs granularity |
chunkOverlap | Boundary loss vs storage |
topK | Evidence vs noise in prompt |
COSINE | Default metric for text vectors |
IVF_FLAT / nlist | Milvus speed/recall tradeoff—revisit as data grows |
VECTOR_DIM | Must match embedding model output |
Myths that break production
- Similar ≠ correct — recall is necessary, not sufficient.
- Smaller chunks ≠ always better — you may drop needed context.
- Vector DB replaces SQL — keep business keys (
book_id) in relational stores; Milvus for similarity. - Dump chunks into prompt — needs structure and rules.
- Demo OK = shipped — still need reindexing, evals, ACL, citations, monitoring.
What to add before “production”
- Observability — query, hits, scores, cited chunks
- Provenance — chapter/section in UI
- Stabilize recall before agentic rerank fireworks
- Extensible metadata — doc type, ACL,
updated_atfor filters later
Summary
The EPUB assistant is a skeleton you can lift to enterprise KBs:
- Loader — how docs enter
- Splitter — retrieval units
- Embedding — comparable vectors
- Milvus — fast semantic recall
- Prompt + LLM — user-facing answers
Milvus’s job is reliable semantic recall at scale—not to be the whole RAG system.