RAG Ingestion: Why Loaders and Splitters Come Before Vector Search
Knowledge does not arrive as LangChain Documents. How loaders normalize sources and splitters set retrieval granularity—with a web-scraping demo.
When people first build RAG, attention goes to vector databases, embedding models, and similarity search. Fair—those decide whether you find the right material at query time.
But in a real knowledge-base project you quickly hit another fact:
Knowledge does not show up as Document objects.
It lives in PDFs, web pages, Notion, Word manuals, video transcripts, email archives. Until you normalize those sources, embedding and retrieval have nothing stable to work on. That is the loader.
Once content is in, documents are often too long. Users care about a paragraph, not a 10,000-token file. Whole-document vectors dilute semantics. That is the splitter.
From an engineering view, RAG is not only “how to search at question time.” It is how knowledge is cleaned, loaded, chunked, and organized on the way in.
You cannot throw raw files into a vector DB
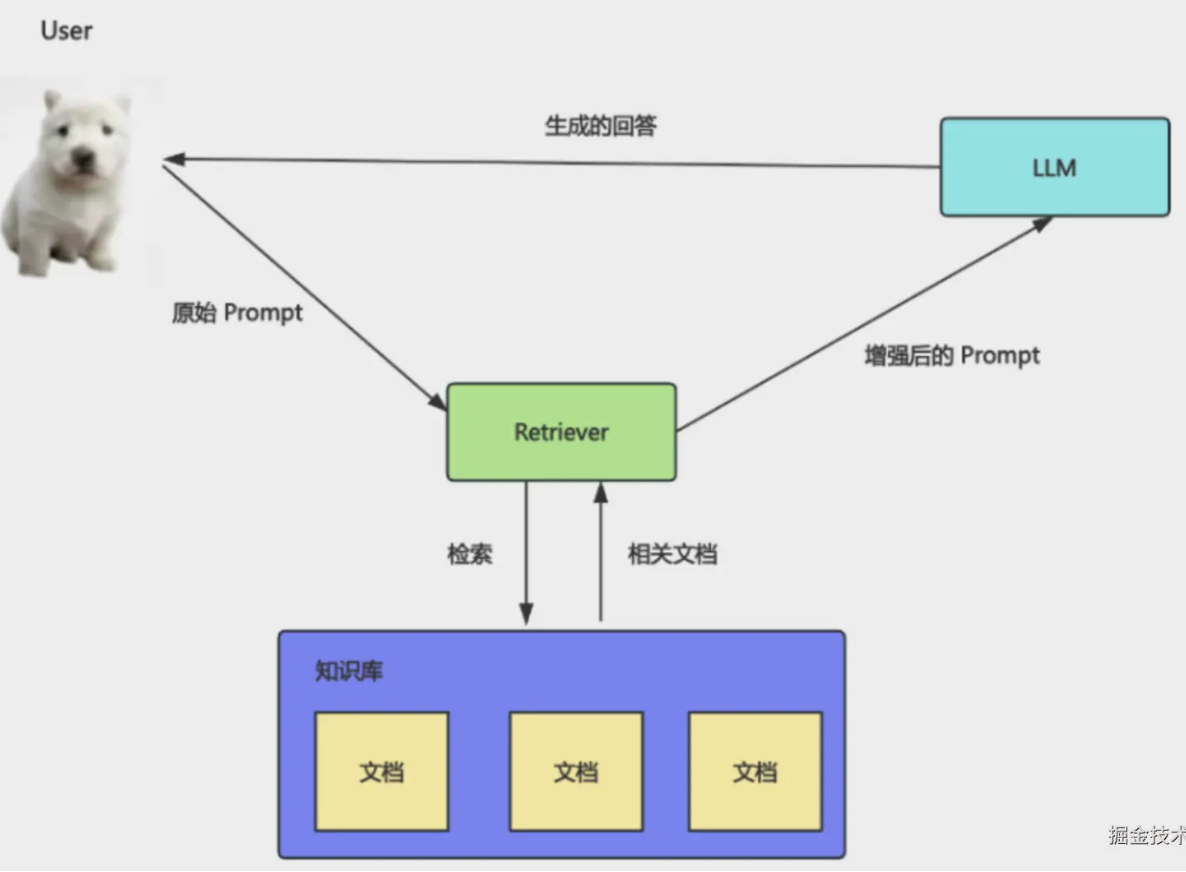
The textbook flow:
- Vectorize the knowledge base
- Retrieve on user questions
- Stuff results into the prompt
- Generate answers
That assumes you already have structured, splittable text. Reality disagrees:
- Web pages mix nav, ads, footers, and body
- PDFs have headers, broken lines, tables
- Word has headings, styles, comments
- Video needs transcription
- DB rows may need field stitching for one semantic unit
Step zero is not embedding—it is converting sources into Document with pageContent + metadata.
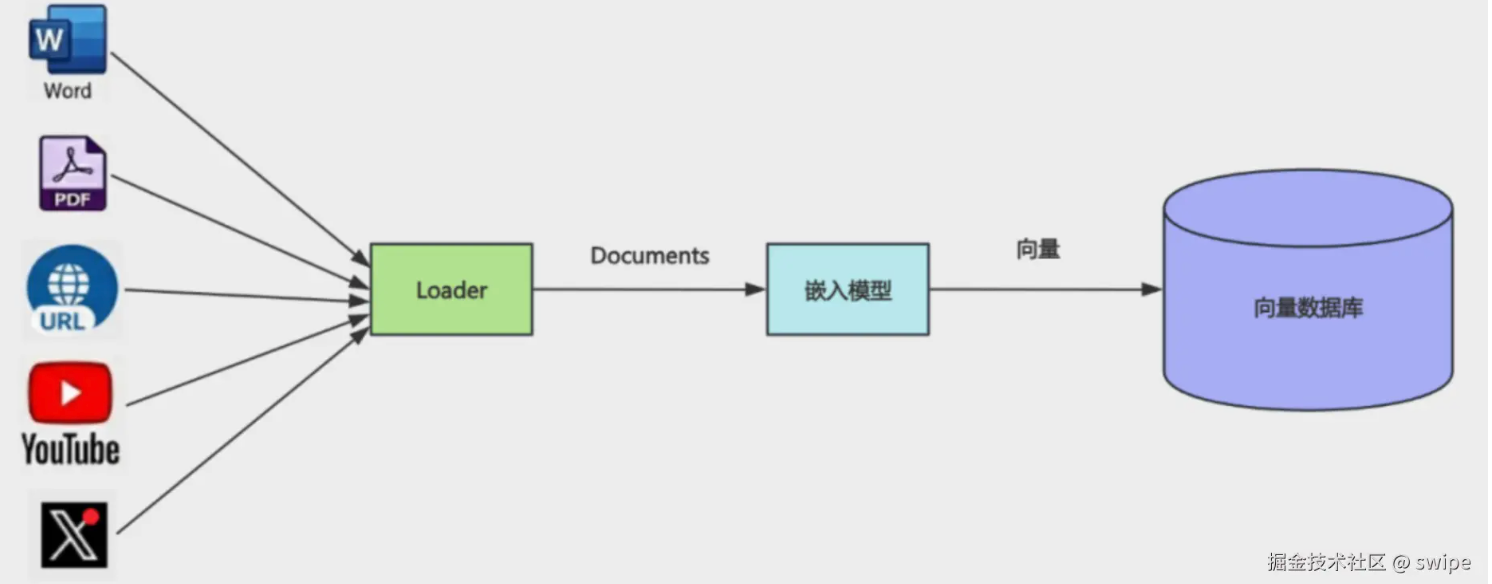
What loaders do
Loaders are the ingestion layer. They do not answer questions or run vector search; they read external data into LangChain Document instances:
pageContent— text that gets embedded and retrievedmetadata— URL, title, author, time, chapter, path
That uniform shape powers chunking, filtering, citations, and ACL later.
Why loading alone is not enough
You can embed a whole page. You usually should not.
A long article encoded as one vector averages many topics. Retrieval returns huge noisy context, costs rise, and the model loses focus. What belongs in the index is usually chunks, not whole files.
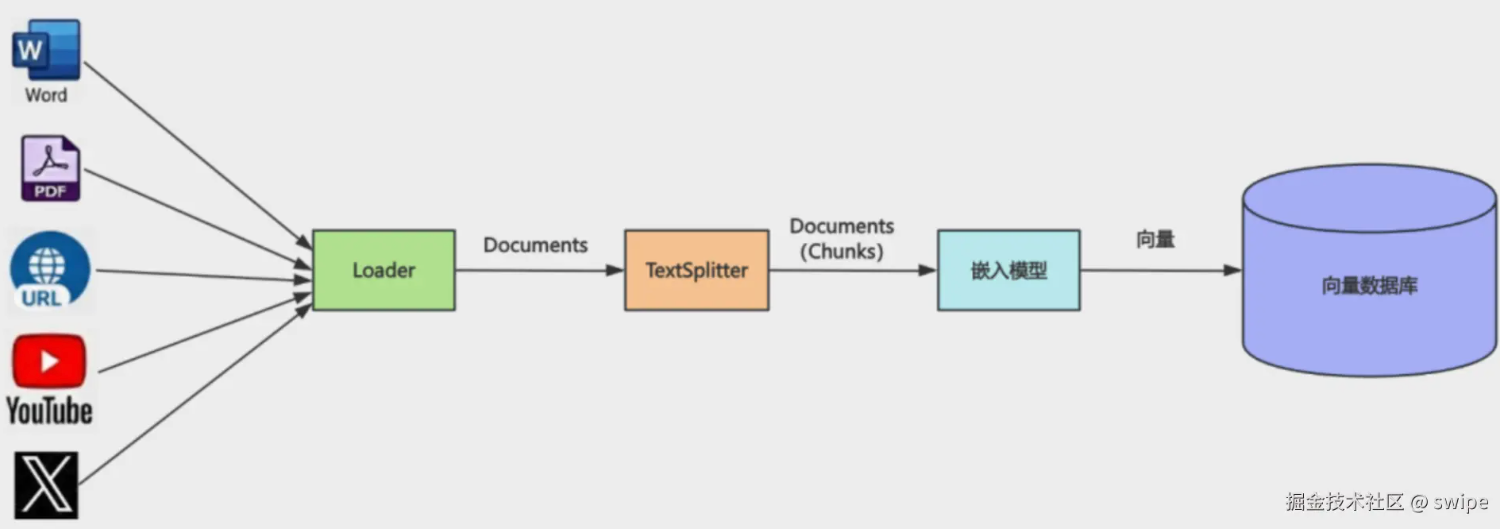
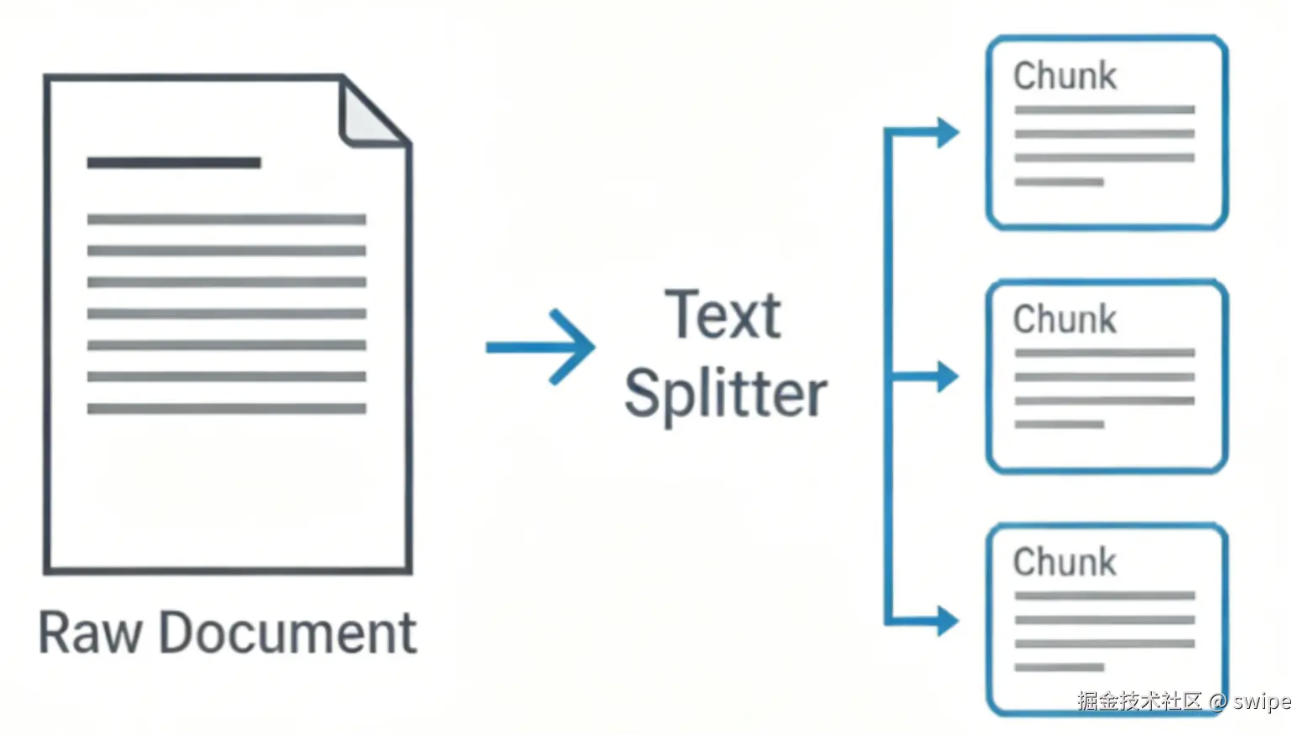
Splitters: balance granularity and coherence
Naïve splitting is not “cut every N characters.”
- Too large — mixed themes, blunt vectors
- Too small — fragments without causality
Goal: balance retrieval granularity and semantic completeness. Hence chunkSize and chunkOverlap—overlap preserves context across boundaries.
Typical ingestion pipeline
- Read raw content (loader)
- Normalize to
Document[] - Split into chunks (splitter)
- Embed chunks
- Store vectors + metadata
- At query time: embed question → retrieve → prompt LLM
Loaders and splitters own the first half. They never talk to the user, but they cap retrieval quality.
Demo: web article → chunks → Q&A
Load with a selector
pnpm add cheerio @langchain/communityimport "dotenv/config";
import "cheerio";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
const loader = new CheerioWebBaseLoader("https://example.com/article", {
selector: ".main-area p",
});
const documents = await loader.load();The selector matters: sidebars, comments, and “related posts” pollute the index if you scrape the whole DOM. Loaders are noise filters, not dumb fetchers.
Split for retrieval
pnpm add @langchain/textsplittersimport { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 400,
chunkOverlap: 50,
separators: [".", "!", "?"],
});
const splitDocuments = await textSplitter.splitDocuments(documents);RecursiveCharacterTextSplitter prefers natural breaks (punctuation for English; use locale-appropriate separators for Chinese). chunkSize / chunkOverlap trade focus vs continuity.
Full mini pipeline
import { ChatOpenAI, OpenAIEmbeddings } from "@langchain/openai";
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
// ... same loader + splitter as above ...
const vectorStore = await MemoryVectorStore.fromDocuments(
splitDocuments,
embeddings,
);
const retriever = vectorStore.asRetriever({ k: 2 });
const question = "How did the father's death change the author's outlook?";
const retrievedDocs = await retriever.invoke(question);
const context = retrievedDocs
.map((doc, i) => `[Passage ${i + 1}]\n${doc.pageContent}`)
.join("\n\n");
const prompt = `
You are a reading assistant. Answer only from the passages.
If evidence is missing, say so. Do not invent facts.
Passages:
${context}
Question:
${question}
`;
const response = await model.invoke(prompt);Think in roles, not API names
load()— pull from the outside worldsplitDocuments()— retrieval-friendly granularityfromDocuments()— build the semantic indexasRetriever()— search interface
Why chunk-then-embed beats whole-document embed
One article may cover childhood, family loss, attitude shifts, and education. A question about the father’s death needs the family chunks, not a single diluted vector over the entire piece. Chunking improves recall precision.
Pitfalls
- Loader noise — bad selectors → junk in the KB
- Chunks too small — incomplete answers
- Chunks too large — relevant but noisy hits
- Missing metadata — no provenance or filters
- One-size-fits-all splitting — legal text ≠ chat logs ≠ API docs
Beyond the demo
- Per-source loaders
- Structure-aware splitting (headings, code blocks)
- Rich metadata (title hierarchy, ACL,
updated_at) - Persistent vector stores
- Hybrid search + rerank
- Eval sets to prove chunking changes moved metrics
Summary
RAG is not only “vectors + LLM.” Before search, knowledge must be accepted, cleaned, and chunked. Loaders standardize input; splitters define what “one retrieval unit” means.
If embeddings and retrievers decide how well you search, loaders and splitters decide whether you can search well at all.