Why RAG Depends on Vector Search: From Embeddings to Semantic Retrieval
How retrieval-augmented generation works in production—why keyword search falls short, what embeddings do, and a runnable LangChain demo.
Anyone new to LLM application development hits the same wall early: the model sounds brilliant until the question goes beyond its training data—internal docs, fresh policies, private knowledge bases—and then it answers with the same confident tone anyway.
That is not malice. It is how large language models work: without extra context, they complete text from statistical patterns in their weights. In engineering terms we call that hallucination.
If you want a usable AI assistant, the first step is usually not “stack more prompts.” It is figuring out how to inject knowledge the model does not have but the business needs. That is where RAG (retrieval-augmented generation) comes in.
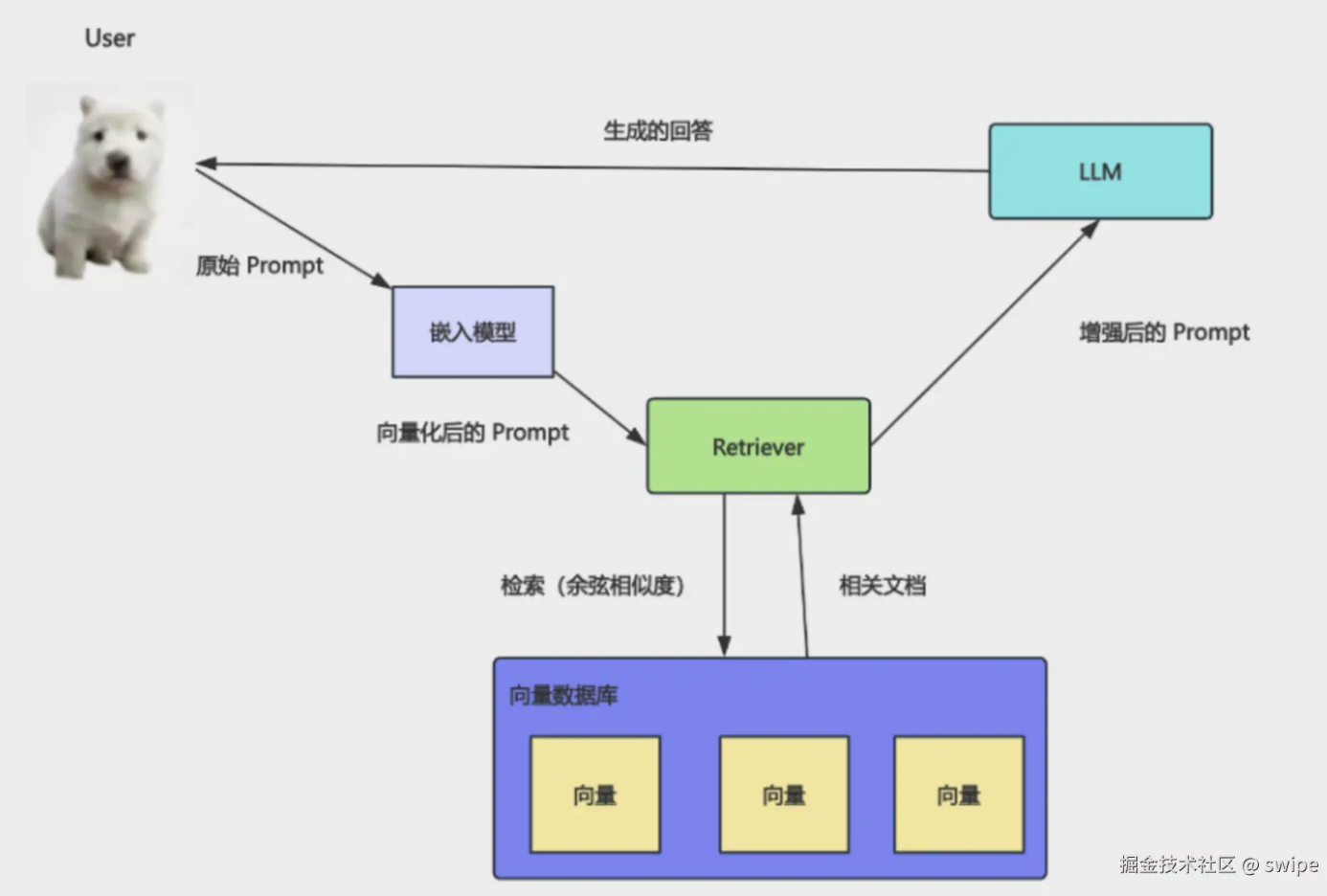
RAG is not magic. Before answering, you retrieve from an external knowledge base, augment the prompt with what you found, then generate from that context. The hard part is this:
When the user’s wording does not match the source document, how do you find the right passages?
This post walks through why keyword search is not enough, how vectors and embeddings relate to vector databases, and a small LangChain demo that runs the full path: embed documents → semantic search → grounded answers.
What problem RAG actually solves
LLMs are good at generating language from context they already have. They do not natively:
- Read your private corporate documents
- Know what happened after training cut off
- Reliably follow facts defined only in your systems
So whenever the answer depends on an external knowledge source, calling the LLM alone is insufficient.
RAG in three steps:
- Retrieval — find content most related to the question.
- Augmentation — inject retrieved text into the prompt.
- Generation — answer using that context.
The value is not “a smarter model” but answers with evidence—enterprise Q&A, doc assistants, support KBs, code search, contract review.
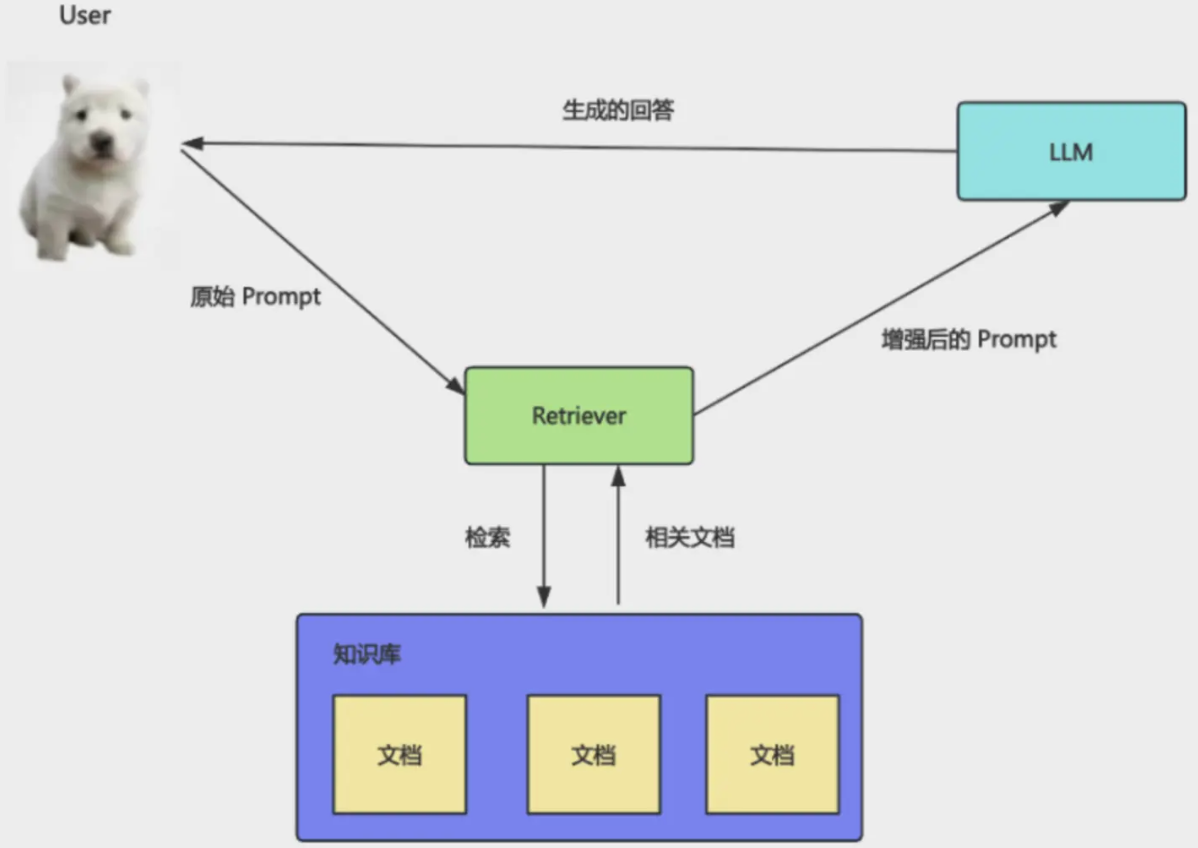
Why keyword search is not enough
Many first implementations use full-text search: store documents, match keywords at query time. That works when the user repeats the same words as the doc. It breaks when they paraphrase.
Document says:
After an employee leaves, account permissions are revoked within 24 hours.
User asks:
When is system access shut off after someone leaves the role?
Same meaning, almost no shared tokens. Keyword search matches surface strings; RAG needs semantic similarity. Keyword-only retrieval is often “works sometimes”; semantic retrieval is what makes it reliable. That path leads to vectors.
What vectors are (and why they encode meaning)
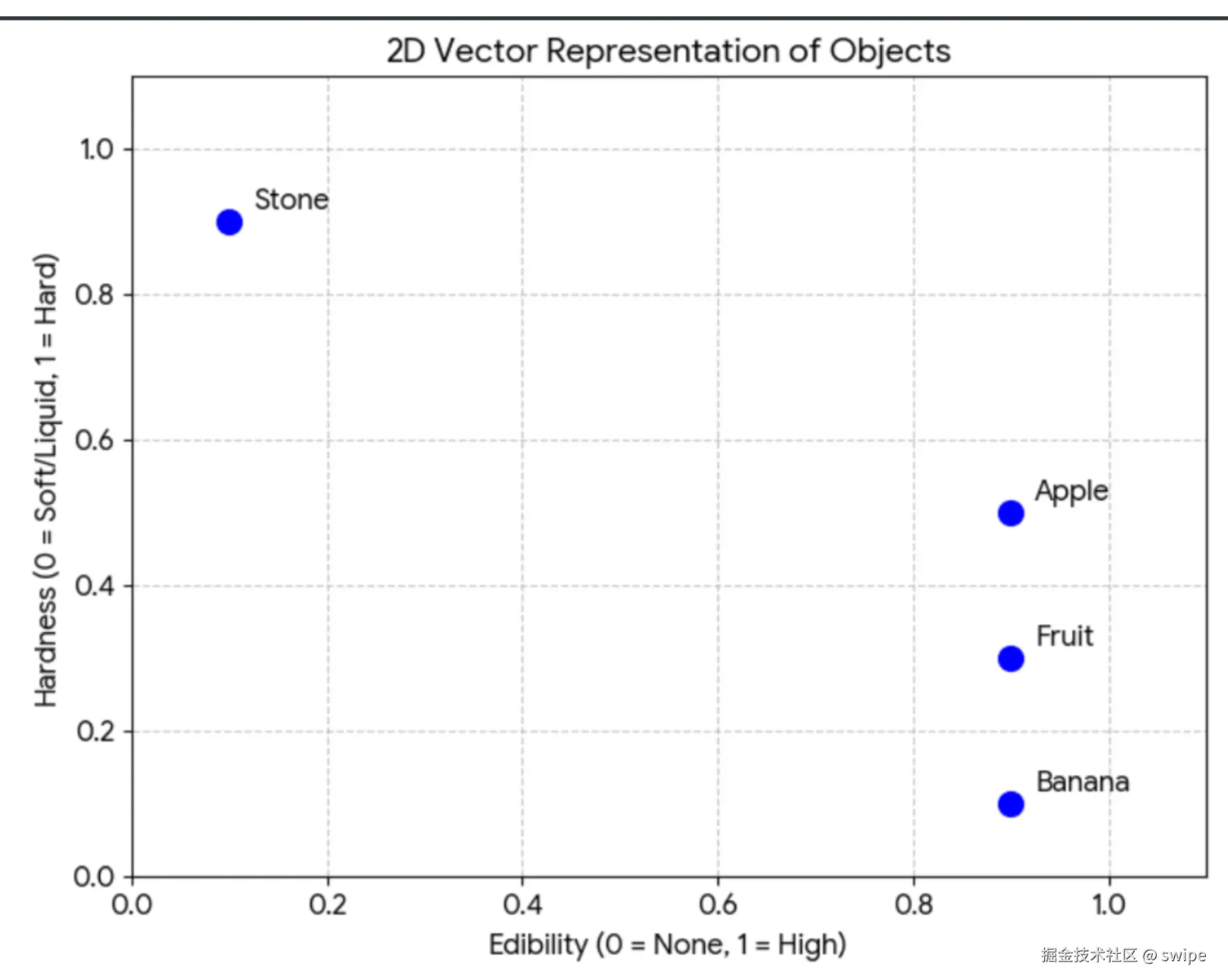
“Turn text into a vector” sounds abstract. A tiny 2D example helps:
- Dimension 1: edibility
- Dimension 2: hardness
Rough positions:
- fruit:
[0.9, 0.3] - apple:
[0.9, 0.5] - banana:
[0.9, 0.1] - stone:
[0.1, 0.9]
An object is not one label but coordinates across semantic dimensions. Apple and banana sit near fruit; stone is far away.
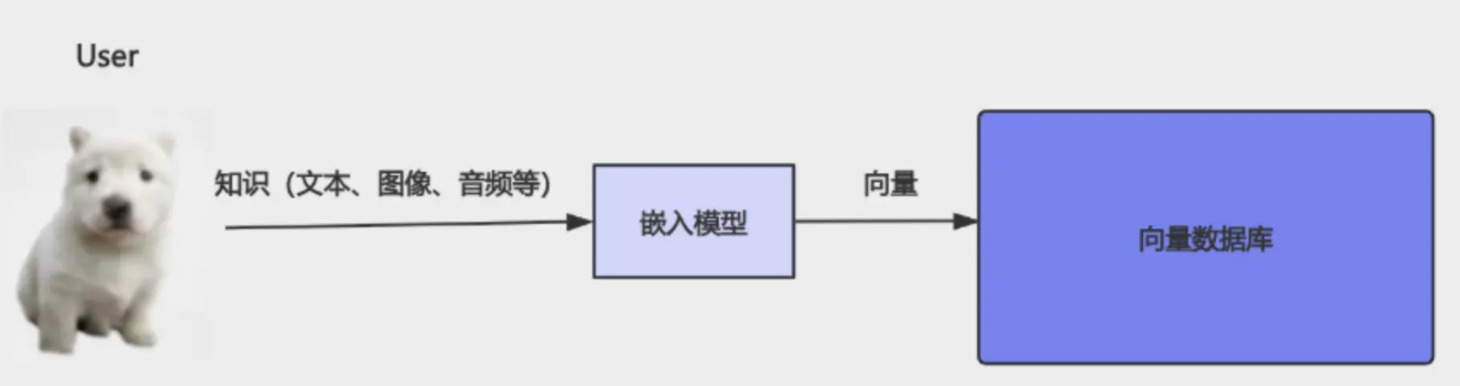
In production we do not hand-pick dimensions. An embedding model learns the mapping.
Embedding models vs LLMs
They are easy to conflate but roles differ:
- LLM — understand context and produce answers
- Embedding model — map text into a vector space where similar meaning sits nearby
Embeddings do not write essays; they enable similarity search. A typical RAG stack uses two model types: one for generation, one for retrieval vectors.
“We already have an LLM, so we skip embeddings” usually fails at scale—you need a searchable semantic space over many documents.
How semantic search works
Once documents and queries are vectors, retrieval is geometry: find vectors closest to the query (cosine similarity, dot product, Euclidean distance, etc.). Closer vectors ≈ closer meaning.
Pipeline:
- Split documents into chunks
- Embed each chunk
- Store vectors + original text + metadata in a vector store
- Embed the user question
- Retrieve top‑k chunks
- Pass chunks to the LLM
Vector DBs store vectors and the text they point to—otherwise you only know “chunk #183 matched,” not what it says.
A business-shaped demo
Knowledge base snippets:
- Expense reimbursement policy
- VPN / remote access rules
- PTO and leave rules
Question:
How does a new hire apply for remote access to internal systems from home?
The user may never say “VPN,” but the intent clearly maps to remote-access policy—ideal for vector retrieval.
Setup
mkdir rag-test
cd rag-test
npm init -y
pnpm add @langchain/core @langchain/openai @langchain/classic dotenv@langchain/openai— chat + embeddings@langchain/core—Documentand primitives@langchain/classic— in-memory vector store for learningdotenv— config
MemoryVectorStore is for teaching, not production. In real systems you would use Milvus, Pinecone, Qdrant, Weaviate, pgvector, etc.
Model config (.env)
OPENAI_API_KEY=sk-xxx
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
MODEL_NAME=qwen-plus
EMBEDDINGS_MODEL_NAME=text-embedding-v3RAG is not locked to one vendor—any compatible API works.
Core script (src/hello-rag.mjs)
import "dotenv/config";
import { ChatOpenAI, OpenAIEmbeddings } from "@langchain/openai";
import { Document } from "@langchain/core/documents";
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
const model = new ChatOpenAI({
model: process.env.MODEL_NAME,
temperature: 0,
apiKey: process.env.OPENAI_API_KEY,
configuration: { baseURL: process.env.OPENAI_BASE_URL },
});
const embeddings = new OpenAIEmbeddings({
model: process.env.EMBEDDINGS_MODEL_NAME,
apiKey: process.env.OPENAI_API_KEY,
configuration: { baseURL: process.env.OPENAI_BASE_URL },
});
const documents = [
new Document({
pageContent:
"Employees working from home must request VPN access before connecting to internal systems. After approval, IT assigns an account and requires two-factor authentication.",
metadata: { category: "remote work", source: "IT access policy" },
}),
new Document({
pageContent:
"Expense reports must be submitted within 15 calendar days. Late submissions need manager justification.",
metadata: { category: "finance", source: "Expense handbook" },
}),
new Document({
pageContent:
"After one year, employees receive 10 days of annual leave. Requests need 3 business days’ notice and manager approval.",
metadata: { category: "HR", source: "Leave policy" },
}),
new Document({
pageContent:
"First-time VPN users must download the client from the security portal and bind a TOTP device. Accounts without 2FA cannot reach the intranet.",
metadata: { category: "remote work", source: "VPN guide" },
}),
];
const vectorStore = await MemoryVectorStore.fromDocuments(documents, embeddings);
const retriever = vectorStore.asRetriever({ k: 2 });
const question =
"How does a new hire request access to internal systems when working from home?";
const retrievedDocs = await retriever.invoke(question);
const scoredDocs = await vectorStore.similaritySearchWithScore(question, 2);
const context = retrievedDocs
.map((doc, index) => `[Source ${index + 1}]\n${doc.pageContent}`)
.join("\n\n");
const prompt = `
You are an internal knowledge assistant. Answer strictly from the sources:
1. Prefer facts in the sources
2. If sources are insufficient, say so explicitly
3. Be concise and actionable
Sources:
${context}
Question:
${question}
`;
const response = await model.invoke(prompt);
console.log(response.content);Responsibilities in the pipeline
Two models — ChatOpenAI generates; OpenAIEmbeddings embeds. Mixing those roles causes confusion about who retrieves vs who answers.
Document — pageContent is what gets embedded and injected; metadata (source, category, version) powers traceability, filtering, and citations.
MemoryVectorStore.fromDocuments — embeds and links vectors to text. The KB becomes a semantic index, not a flat file list.
asRetriever({ k: 2 }) — returns top matches. Too few chunks starve the model; too many add noise, cost, and drift. Tuning k is part of RAG design.
Retrieve before generate — retriever.invoke(question) then structured context in the prompt. Without that step, the model only has parametric knowledge.
Prompt constraints — “use sources,” “admit ignorance,” “be actionable” reduce confident fabrication even when retrieval is right.
What you should see
Hits should favor VPN / remote-access chunks, not PTO or expenses. The answer should cite your policies, not generic internet advice.
This is not production RAG yet
You still need chunking strategy, persistent vector stores, hybrid search + rerank, evaluation (recall, groundedness), and ops. “Documents are in the vector DB” is the starting line, not the finish.
Common confusions
- RAG ≠ vector database — the DB is one piece of the retrieval layer.
- Embeddings do not answer — they only enable search.
- Good retrieval ≠ guaranteed correct answer — generation constraints still matter.
- Keywords are not dead — SKUs, error codes, and exact IDs often need keyword or hybrid retrieval.
Engineering takeaway
RAG is an external, updatable, traceable knowledge layer around the LLM:
- LLM — language
- Embeddings — semantic coordinates
- Vector store — nearest-neighbor search
- Retriever — recall interface
- Prompt — inject evidence into generation
Summary
RAG is about grounded answers, not longer answers. Semantic retrieval needs embeddings and a vector store; the retriever feeds the LLM evidence. Once you understand why vectorization exists and how retrieval joins generation, chunking, reranking, hybrid search, and agentic retrieval become the natural next steps.