The Six Pillars of Coding Agents (and How to Evaluate Any New Product)
Agent loop, tools, context, memory, multi-agent, and harness—one framework I use instead of chasing every new launch.
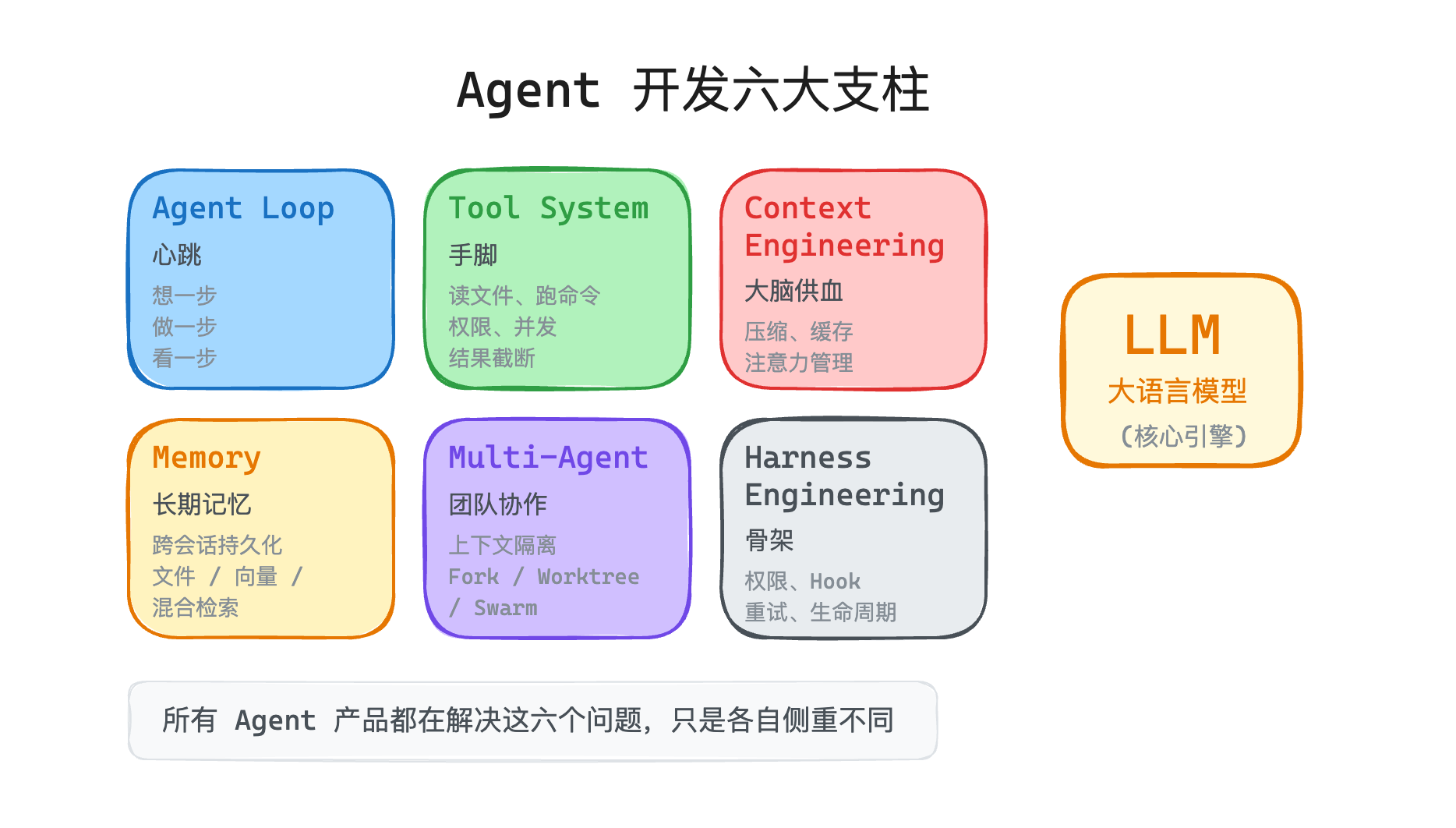
Every coding agent looks different in the UI, but most products wrestle with the same six problems. I use this map when comparing Cursor, Claude Code, Copilot agents, or internal tools—instead of feature checklists that age in a month.
One request, six systems
Say you ask an agent to refactor formatDate in src/utils.ts to use dayjs instead of moment. Between your enter key and “done,” roughly this happens:
- Plan the next step — read files, check dependencies, edit, test. That is the agent loop (think → act → observe). Without it, you only have a chatbot.
- Touch the repo — read, write, shell. That is the tool system (schemas, permissions, concurrency).
- Stay within context limits — remember what changed in nine files without stuffing 200k tokens of noise. That is context engineering.
- Remember team conventions across sessions — “we use pnpm.” That is memory (session vs long-term).
- Fork exploration — a sub-agent scans the repo and returns a short summary so the parent thread stays clean. That is multi-agent (usually for context isolation, not role-play theater).
- Stay safe and operable — confirm
rm -rf, retry APIs, handle Ctrl+C, detect infinite loops. That is harness engineering.
| Pillar | One line | Analogy |
|---|---|---|
| Agent loop | Repeat think → act → observe | Heartbeat |
| Tool system | Files, shell, APIs | Hands |
| Context engineering | What enters the window this turn | Blood supply |
| Memory | Facts across sessions | Long-term recall |
| Multi-agent | Split work / isolate context | Team lanes |
| Harness | Policy, retries, hooks, lifecycle | Skeleton |
New launches are easier to read through these lenses: what did they change in the loop, context, or harness?
Depth most demos skip
Agent loop — Production loops add truncation recovery, layered retries, seven-ish exit reasons (user abort, max turns, hook veto, context overflow), and streaming tool execution. See who owns the loop.
Tool system — Accuracy often drops as tool count grows (deferred loading, sandbox scripts, “mask don’t remove” for cache stability).
Context engineering — Fifty tool calls × 2k tokens each fills a window fast. “Lost in the middle” means curating beats stuffing. Common tactics: offload to disk, compress/summarize, retrieve (RAG), isolate (sub-agents), cache (prompt/KV).
Memory — From a plain MEMORY.md file to SQLite + hybrid search—pick by audience size and debuggability, not hype.
Multi-agent — Sub-agents mainly compress exploration into a small parent message; worktrees add filesystem isolation.
Harness — The difference between a demo and something you trust on a client repo.
How this connects to my other writing
- Loop mechanics → Chatbot vs Agent
- Build a minimal loop → Mini Claude Code
- Long-term recall → Memory as context budget
- Project-level AI workflow → Rules, Skills, SDD
Products change weekly; these problems do not. That is what I optimize for when shipping agent features for clients.